Entry 01 · Ch. 1
01
Survey
Foundations
Published 2006
The Berkeley View: What Parallel Computing Means After the Free Lunch Ended
"If single-core clock speed has plateaued, what does scalable computation actually require — and what does that mean for how we design ML systems today?"
In 2006, Asanovic et al. published The Landscape of Parallel Computing Research: A View from Berkeley — a document that reframed the entire field at the moment when Moore's Law stopped delivering free single-threaded performance. The paper identified 13 "dwarfs" — computational patterns that appear repeatedly across scientific and commercial workloads — and argued that future hardware and software co-design must target these patterns explicitly.
This survey traces the Berkeley View's core arguments, maps each dwarf to modern ML workloads (dense linear algebra → transformer attention; graph traversal → GNN message passing; structured grid → convolutional operations), and examines which predictions aged well and which were superseded by GPU architecture. The key insight the paper got right: memory bandwidth, not compute, would become the dominant bottleneck — a finding that directly informs the thesis work on neural retrieval under bandwidth constraints.
Core insight
The Berkeley dwarfs are not a taxonomy of algorithms — they are a taxonomy of memory access patterns. The reason parallel speedup plateaus at 4–8 workers in MIPS retrieval is the same reason it plateaued in 2006 grid computations: DRAM bandwidth is shared, and no amount of additional compute cores changes that constraint.
PDF
Survey: Parallel Programming Post Berkeley View (2006) — Structured Summary
View →
Entry 02 · Ch. 2
02
Implementation
Benchmarking
DistilBERT
From Sieve to MIPS: Parallel Decomposition in Practice
"The Sieve of Eratosthenes is trivially parallel — until you think carefully about communication. What does that teach us about decomposing neural retrieval?"
The Sieve of Eratosthenes is a canonical parallel algorithm: embarrassingly parallel at first glance, but deceptively instructive about data decomposition, synchronization barriers, and the cost of global reduction. This entry implements a parallel sieve, analyzes where parallelism breaks down (the broadcast of each prime to all workers), and uses that analysis as a lens for the more complex problem of Top-k MIPS.
The parallel MIPS implementation applies the same Map-Reduce decomposition: partition the corpus across workers (Map), compute local Top-k scores per chunk, merge candidates into global Top-k (Reduce). Benchmarked on a 24-core CPU with a 5,000-document DistilBERT corpus (d=768). Results: 2 workers → 2.3× speedup, 4 workers → 5.2×, 8 workers → 5.9×, 12 workers → 5.4× (saturation). The degradation beyond 8 workers mirrors the sieve's broadcast bottleneck: once DRAM bandwidth is saturated, adding threads generates contention rather than throughput.
Core insight
Parallel speedup curves are not monotonic — they have a peak determined by the ratio of compute to memory bandwidth. For streaming workloads like MIPS, this peak arrives early. Designing for the peak (not the theoretical maximum) is what separates practical parallel algorithm design from textbook analysis.
IPYNB
Parallel Top-k MIPS for Neural Retrieval using DistilBERT — Full Implementation + Benchmarks
View →
PY
Sieve of Eratosthenes — Parallel Implementation with Concurrency Analysis
View →
Entry 03 · Ch. 3
03
Graph Algorithms
Visualization
Task Agglomeration
Floyd-Warshall and the Geometry of Task Agglomeration
"All-pairs shortest path is a classic parallel algorithm — but the interesting question isn't how to parallelize it, it's how agglomeration changes the communication topology entirely."
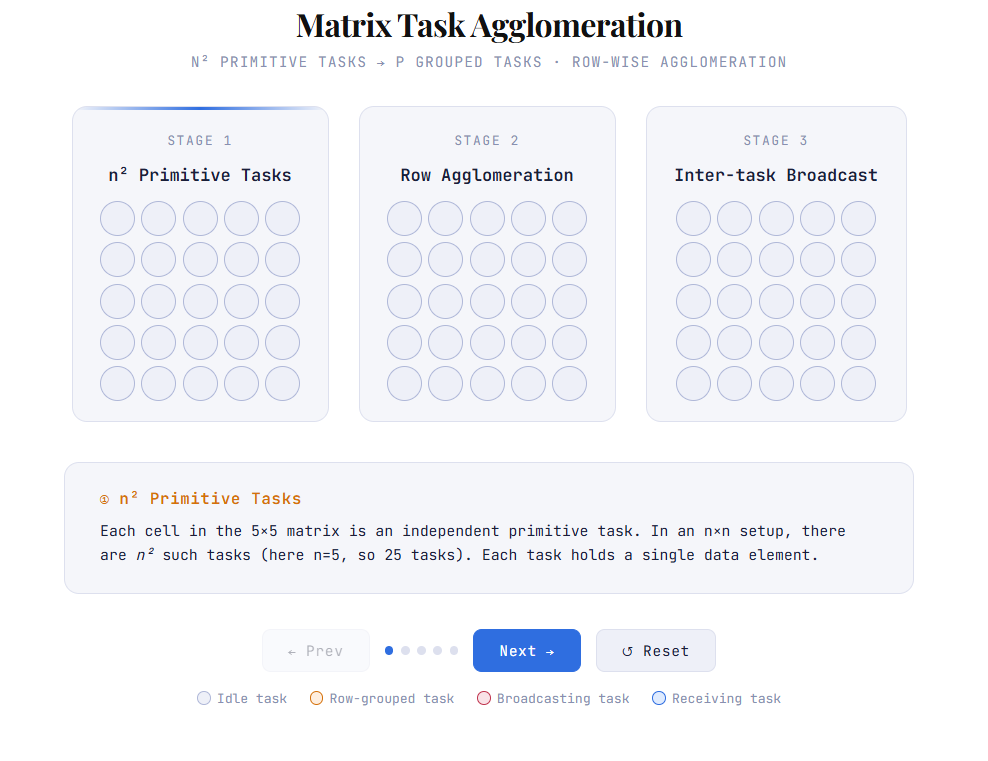
Floyd-Warshall computes all-pairs shortest paths through n³ relaxation steps. Each step k reads a broadcast row and updates a 2D submatrix — a structure that looks parallel but is governed by a data wavefront dependency: step k cannot begin until step k−1 completes across the entire matrix. Naive fine-grained parallelism creates O(n²) tasks with O(n) communication steps each.
Task agglomeration collapses fine-grained tasks into coarser units assigned to processors, trading task count for communication volume. This entry analyzes the agglomeration decision in Floyd-Warshall — how block decomposition reduces communication from O(n²) messages to O(p√p) — and visualizes the broadcast propagation pattern across the log-tree communication structure. The animated artifact makes the phase transitions legible: idle tasks, local computation, agglomerated grouping, and broadcast diffusion across the processor grid.
For geospatial ML applications, Floyd-Warshall's structure is directly relevant: graph-based terrain analysis, road network routing, and GNN message passing all exhibit similar wavefront dependency patterns at scale.
Core insight
Agglomeration is not just a performance optimization — it is a communication topology decision. The right agglomeration strategy for Floyd-Warshall (2D block decomposition) is fundamentally different from the right strategy for MIPS (1D row decomposition), because the dependency structure of the algorithm determines which decompositions are communication-efficient.
Visualizations
Three-scene interactive: primitive n² task grid → row agglomeration → log-tree broadcast propagation. Click ▶ Animate in each scene. Demonstrates how coarsening task granularity eliminates intra-row communication and changes the broadcast topology from O(n²) messages to O(⌈log p⌉) steps.
Static visualization of the Floyd-Warshall wavefront pattern showing task dependencies and communication flow across the processor grid.
HTML
Task Agglomeration & Broadcast Communication — Interactive Animation
Open standalone →
Remaining chapters
// forthcoming as coursework progresses